<!-- AI_TASK_START: AI标题翻译 -->
[解决方案] AWS Direct Connect 覆盖网络隧道故障切换时间优化最佳实践
<!-- AI_TASK_END: AI标题翻译 -->
<!-- AI_TASK_START: AI竞争分析 -->
# 解决方案分析:优化 AWS Direct Connect 上的覆盖隧道故障转移时间
## 解决方案概述
该解决方案旨在优化基于 **AWS Direct Connect (DX)** 的混合云网络连接的 **故障转移时间**,特别是针对运行在 DX 之上的 **覆盖隧道**(如 AWS Site-to-Site VPN 或 TGW Connect)。核心目标是将网络故障后的恢复时间从分钟级降低至亚秒级(数百毫秒),从而满足企业关键业务对高可用性(HA)的严苛要求。该方案通过优化底层(Underlay)的故障检测机制和上层(Overlay)的隧道架构设计,系统性地解决了混合云连接中的网络收敛缓慢问题,确保在链路中断时业务流量能够快速、平滑地切换至备用路径。
## 核心技术与实施路径
### 1. 优化底层连接:BGP 计时器与 BFD
- **BGP 计时器调整**
- **默认行为**: DX VIF 默认的 BGP hold time 为90秒,这意味着在最坏情况下,检测到链路故障需要长达90秒。
- **优化方式**: 用户可以在本地路由器上将 BGP hold time 缩短至最低3秒,AWS 会自动协商匹配该值。
- **风险**: 过于激进的计时器(如设置过低)可能在网络瞬时抖动时导致不必要的 BGP 会话重置,影响网络稳定性。
- **BFD (双向转发检测)**
- **技术原理**: BFD 是一种轻量级的、独立于路由协议的快速故障检测机制。它通过高频发送控制报文来监控链路状态。
- **实施**: AWS 在 DX VIF 上自动启用了异步 BFD。用户只需在自己的路由器上配置 BFD,并将其与 BGP 会话关联即可。
- **效果**: 通过将 BFD 检测间隔设置为最低支持的300毫秒,并将乘数设为3,可以将底层链路的故障检测时间缩短至 **300毫秒**,相比最低3秒的 BGP 计时器,性能提升了 **90%**。
- **配置示例 (Cisco IOS-XE)**:
```
! 接口配置
interface TenGigabitEthernet1/0/0.100
bfd interval 300 min_rx 300 multiplier 3
! BGP 配置
router bgp 65000
neighbor 169.254.100.2 fall-over bfd
```
### 2. 优化覆盖隧道架构:Pinned vs. Unpinned
- **Pinned Tunnels (固定隧道)**
- **架构**: 隧道的源 IP 地址直接使用 DX VIF 的接口 IP。这导致隧道被“固定”到单一的物理链路上。
- **故障转移逻辑**: 当底层的 DX 连接发生故障时,不仅需要底层 BGP/BFD 检测到故障,还需要上层的隧道协议(如 TGW Connect 的 BGP)自身超时(默认为30秒)后,流量才能切换。总故障时间是 **底层检测时间 + 上层隧道超时时间** 的总和。
- **缺点**: 故障恢复时间长,存在双重延迟。
- **Unpinned Tunnels (非固定隧道)**
- **架构**: 隧道的源 IP 地址使用路由器上的逻辑接口(如 Loopback 接口)的 IP。该 Loopback IP 地址通过所有冗余的 DX VIF 向 AWS宣告。
- **故障转移逻辑**: 当某条 DX 连接故障时,底层路由(BGP)会快速收敛,将流量切换到另一条可用的 DX 链路上。由于隧道的源/目 IP 地址(Loopback 和 TGW 端点)依然可达,上层隧道本身 **不会中断**,也无需等待其协议超时。总故障时间 **仅取决于底层的故障检测时间**。
- **优点**: 实现了近乎透明的快速故障转移,是官方推荐的最佳实践。
- **要求**: 需要在本地多台路由器之间配置路由协议(如 iBGP)以确保 Loopback 接口的互相可达性,并需要通过 BGP 路径属性(如 Local Preference)来控制流量路径,实现对称路由。
---
## 故障转移时间对比分析
下表总结了不同配置组合下的故障转移性能:
| **隧道配置类型** | **底层DX VIF故障检测** | **底层收敛时间** | **上层TGW Connect收敛时间** | **总故障时间** | **实现复杂度** | **关键考量** |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **Pinned (固定)** | 默认BGP计时器 | 90 秒 | 30 秒 | ~120 秒 | 低 | 恢复速度最慢 |
| | 最低BGP计时器 | 3 秒 | 30 秒 | ~33 秒 | 低 | BGP流量增加 |
| | 最低BFD计时器 | 300 毫秒 | 30 秒 | ~30.3 秒 | 中 | 需硬件支持BFD |
| **Unpinned (非固定)** | 默认BGP计时器 | 90 秒 | 不触发 | ~90 秒 | 高 | 内部路由配置复杂 |
| | 最低BGP计时器 | 3 秒 | 不触发 | ~3 秒 | 高 | BGP流量增加 |
| | 最低BFD计时器 | 300 毫秒 | 不触发 | **~300 毫秒** | 高 | 需硬件支持BFD且内部路由复杂 |
> **分析结论**: 采用 **Unpinned Tunnels** 架构并结合 **BFD**,可将故障转移时间从默认的90秒优化至300毫秒,恢复速度提升高达 **99.7%**。
## 方案客户价值
- **极致的高可用性**: 将混合云网络的 RTO(恢复时间目标)降至亚秒级,为关键业务应用提供电信级的网络可靠性保障。
- **降低业务中断损失**: 快速的网络恢复能力可最大程度减少因网络故障导致的业务中断、收入损失和品牌声誉损害。
- **符合架构最佳实践**: 遵循 AWS Well-Architected 框架中的“预判故障”设计原则,构建具备高弹性和自愈能力的云网络架构。
- **量化性能提升**: 相比默认配置,Unpinned 架构本身可减少 **33%** 的故障转移时间;结合 BFD 后,可实现 **99.7%** 的恢复时间缩短。
## 涉及的相关 AWS 产品
- **AWS Direct Connect**: 提供专线连接的底层网络服务。
- **AWS Transit Gateway**: 作为云上网络枢纽,用于连接 VPC 和本地网络。
- **Transit Gateway Connect**: TGW 的一种附件类型,通过 GRE 隧道提供与本地网络设备的高带宽集成。
- **AWS Site-to-Site VPN**: 提供基于 IPsec 的加密隧道连接。
- **Amazon CloudWatch**: 用于监控 DX 连接状态、BGP 和 BFD 会话指标。
## 技术评估
- **优势**
- **性能卓越**: 结合 Unpinned 架构和 BFD 的方案是当前实现混合云快速故障倒换的业界领先实践,可达到亚秒级的收敛速度。
- **分层解耦**: 将底层链路的故障检测与上层隧道的状态解耦,设计思路清晰,避免了问题叠加导致的恢复延迟。
- **标准化技术**: 方案基于 BGP、BFD 等业界标准协议,与主流网络设备厂商兼容性良好。
- **局限性与实施考量**
- **实现复杂度高**: 最佳的 Unpinned 方案要求企业具备较高的网络技术能力,需要精通 BGP 路由策略(如 Local Preference、AS_PATH Prepending)和内部路由设计,以确保对称路由并避免环路。
- **硬件依赖性**: 启用 BFD 需要本地路由器硬件的支持,并可能增加设备 CPU 负载,需要进行充分的性能规划和测试。
- **优化范围有限**: BFD 仅能加速 DX VIF 物理链路的故障检测。对于覆盖隧道端点(如 TGW)自身的故障,仍然依赖隧道协议自身的保活和超时机制。
<!-- AI_TASK_END: AI竞争分析 -->
<!-- AI_TASK_START: AI全文翻译 -->
# 优化 AWS Direct Connect 上叠加隧道故障切换时间的最佳实践
**原始链接:** [https://aws.amazon.com/blogs/networking-and-content-delivery/best-practices-to-optimize-failover-times-for-overlay-tunnels-on-aws-direct-connect/](https://aws.amazon.com/blogs/networking-and-content-delivery/best-practices-to-optimize-failover-times-for-overlay-tunnels-on-aws-direct-connect/)
**发布时间:** 2025-08-21
**厂商:** AWS
**类型:** BLOG
---
## 简介
在混合连接中,优化的故障切换时间对于满足现代企业工作负载的可用性关键绩效指标 (Key Performance Indicators, KPIs) 至关重要。当在 [Amazon Web Services (AWS) Direct Connect](https://aws.amazon.com/directconnect/) 上实施叠加隧道 (overlay tunnels) 时,这一点尤其重要,例如使用 IPSec 隧道的 [AWS Site-to-Site VPN](https://docs.aws.amazon.com/vpn/latest/s2svpn/VPC_VPN.html) ,或使用通用路由封装 (Generic Routing Encapsulation, GRE) 隧道的 [Connect 附件 (Connect Attachments)](https://docs.aws.amazon.com/vpc/latest/tgw/tgw-connect.htm) 。正确的配置可以将故障切换时间从数分钟缩短至毫秒级,从而显著提高网络可靠性。遵循 [架构完善框架 (Well-Architected Framework)](https://aws.amazon.com/architecture/well-architected/) 中 [卓越运营支柱 (Operational Excellence pillar)](https://docs.aws.amazon.com/wellarchitected/latest/framework/operational-excellence.html) 的 [‘预测故障’ (Anticipate Failure)](https://docs.aws.amazon.com/wellarchitected/latest/framework/oe-design-principles.html) 设计原则,本文概述了在保持本地环境与 AWS 环境之间弹性网络连接的同时,将停机时间最多减少 99.7% 的运营最佳实践。例如,我们的分析表明,仅选择非锚定 (unpinned) 隧道配置而非锚定 (pinned) 隧道配置,就可以将故障切换时间减少 33%。
一个具有弹性的 Direct Connect 基础设施是实现高可用性混合连接的基础。在深入探讨叠加隧道优化之前,读者应先熟悉 [Direct Connect 弹性工具包 (Direct Connect Resiliency Toolkit)](https://docs.aws.amazon.com/directconnect/latest/UserGuide/resiliency_toolkit.html) 并理解 [主/主 (Active/Active) 和主/备 (Active/Passive) 配置](https://docs.aws.amazon.com/architecture-diagrams/latest/active-active-and-active-passive-configurations-in-aws-direct-connect/active-active-and-active-passive-configurations-in-aws-direct-connect.html) 。本文使用 [Direct Connect 高弹性:多站点非冗余部署模型](https://aws.amazon.com/directconnect/resiliency-recommendation/) 作为参考架构来演示这些优化技术,如下图所示。
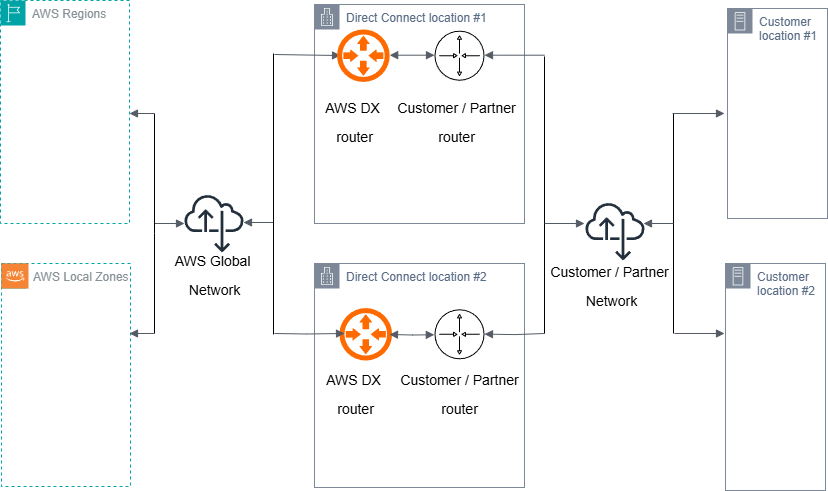
图 1: 采用高弹性模型的 Direct Connect 连接
在优化 Direct Connect 上的叠加隧道故障切换时间时,需要考虑两个关键方面:
1. 底层连接的故障切换速度
2. 叠加隧道的行为
首先,我们将研究如何优化 BGP 计时器并实施 BFD,以改善底层 Direct Connect 的故障检测和收敛速度。然后,我们将探讨不同的隧道配置方法——锚定和非锚定——如何显著影响整体故障切换性能。尽管 BGP 计时器优化有助于在 Direct Connect 层面更快地检测故障,但隧道配置策略决定了您的叠加流量能够多快地通过备用路径恢复。理解并实施这两个方面对于在您的混合网络架构中实现最佳故障切换时间至关重要。
Direct Connect 需要 [虚拟接口 (Virtual Interfaces, VIFs)](https://docs.aws.amazon.com/directconnect/latest/UserGuide/create-vif.html) ,可以是公有 (Public)、私有 (Private) 或中转 (Transit) VIF。创建一个 Direct Connect VIF 涉及两个关键步骤:交换 VLAN 标签和建立边界网关协议 (Border Gateway Protocol, BGP) 会话。如果您想了解更多关于 Direct Connect VIF 的信息,可以参考 [我们的文档](https://docs.aws.amazon.com/directconnect/latest/UserGuide/Welcome.html) 。
在本文中,我们重点关注以下两个选项:
1. BGP 保持计时器
2. 在 Direct Connect 上建立隧道
## BGP 计时器及其对故障切换时间的影响
Direct Connect VIF 的故障切换时间主要取决于 BGP 的故障切换计时。有两个关键计时器需要考虑:
1. **BGP 保持时间 (BGP hold time)**:这是 BGP 路由器在宣布对等体失效并终止 BGP 会话之前,等待接收 keepalive 或更新消息的最长时间。在 Direct Connect VIF 上,[默认](https://docs.aws.amazon.com/directconnect/latest/UserGuide/limits.html) 的保持计时器是 90 秒,可以减少到最低 3 秒。
2. **BGP keepalive 计时器**:该计时器决定了 BGP 路由器向其对等体发送 keepalive 消息的间隔,以维持 BGP 会话并表明活动状态。在 Direct Connect VIF 上,[默认](https://docs.aws.amazon.com/directconnect/latest/UserGuide/limits.html) 的 keepalive 计时器是 30 秒,可以减少到最低 1 秒。
为了缩短故障切换时间,用户可以在其路由器上减少 BGP 计时器。AWS 在收到 BGP 消息后会自动协商以匹配这些值。但是,BGP 计时器无法通过 [AWS 管理控制台 (AWS Management Console)](https://aws.amazon.com/console/) 进行配置。尽管减少 BGP 计时器值可以改善故障切换时间,但不建议设置得过低,因为这可能会损害网络稳定性。过于激进的计时器设置可能在短暂的网络拥塞或 CPU 峰值期间导致不必要的 BGP 会话重置。每次重置都会触发路由重新收敛,这可能会影响网络稳定性和应用流量。在拥有多个 BGP 会话的环境中,这一点尤其关键,因为必须谨慎管理路由器资源。
为了更快地检测故障并进行故障切换,我们建议启用双向转发检测 (Bidirectional Forwarding Detection, BFD)。异步 BFD 在 AWS 侧的 Direct Connect VIF 上是自动启用的。但是,您必须配置您的路由器,为您的 Direct Connect 连接 [启用异步 BFD](https://repost.aws/knowledge-center/enable-bfd-direct-connect) 。以下是在运行 IOS-XE 16.1 的 Cisco ASR 1002-HX 设备上启用 BFD 的 CLI 配置输出。
```
! Interface Configuration
interface TenGigabitEthernet1/0/0.100
description DX-VIF-1
encapsulation dot1q 100
ip address 169.254.100.1 255.255.255.252
bfd interval 300 min_rx 300 multiplier 3
no shutdown
! BGP Configuration
router bgp 65000
neighbor 169.254.100.2 remote-as 64512
neighbor 169.254.100.2 fall-over bfd
```
在前面的示例中,显示的是链路本地地址 (Link-Local address)。在配置 Direct Connect VIF 时,您可以使用 RFC 1918 指定自己的 IP 地址或使用其他寻址方案,也可以选择由 AWS 分配的 IPv4 /29 CIDR 地址。这些 CIDR 地址是从 RFC 3927 的 169.254.0.0/16 IPv4 链路本地地址范围中分配的,用于点对点连接。这些点对点连接应仅用于您的客户网关路由器和 Direct Connect 端点之间的 eBGP 对等。对于 VPC 流量或隧道目的,例如 Site-to-Site 私有 IP VPN 或 [AWS Transit Gateway](https://aws.amazon.com/transit-gateway/) Connect,AWS 建议在您的客户网关路由器上使用环回 (loopback) 或 LAN 接口作为源或目标地址,而不是使用点对点连接。更多详情请参考 Direct Connect [文档](https://docs.aws.amazon.com/directconnect/latest/UserGuide/create-private-vif-for-gateway.html) 。
影响故障切换时间的关键 BFD 组件是:
1. **最小存活检测间隔 (Minimum liveness detection interval)**:这是您的路由器应该期望接收到的 BFD 控制数据包之间的最小间隔。较短的间隔可以实现更快的故障检测,但会增加 CPU 开销。在 Direct Connect 上,[支持的](https://docs.aws.amazon.com/directconnect/latest/UserGuide/limits.html) 最小值为 300 毫秒。
2. **最小 BFD 乘数 (Minimum BFD multiplier)**:这是在宣布会话中断之前可以丢失的 BFD 数据包数量。总的故障检测时间是通过将此值与检测间隔相乘得出的。[支持的](https://docs.aws.amazon.com/directconnect/latest/UserGuide/limits.html) 最小值为 3。
在 Direct Connect VIF 上使用 BFD 可以显著减少故障切换时间。使用支持的最小可配置值进行比较显示:
* **不使用** BFD:BGP 故障切换时间 = 3 秒
* **使用** BFD:故障切换时间 = 300 毫秒 (0.3 秒)
这表示故障切换时间减少了 **90%**,使 BFD 成为一种用于故障检测和恢复的效率显著更高的解决方案。
请务必咨询您的网络硬件供应商,以确定适用于您特定设备的 BGP 计时器和 BFD 设置的最小推荐值。有关 BFD 的详细信息,请参阅 [RFC5880](https://datatracker.ietf.org/doc/html/rfc5880) 。
## 在 Direct Connect 上建立隧道
对于实施叠加隧道 ([Site-to-Site VPN](https://docs.aws.amazon.com/vpn/latest/s2svpn/VPC_VPN.html) 或 [Connect 附件](https://docs.aws.amazon.com/vpc/latest/tgw/tgw-connect.htm) ) 到 Transit Gateway 的用户来说,Direct Connect 充当底层 (underlay) 连接。尽管这些叠加选项提供了增强的连接功能,但它们引入了更多影响整体故障切换性能的协议依赖和计时因素。理解这些因素对于优化混合网络架构中的故障切换时间至关重要。
## 隧道配置方法
在本节中,我们介绍两种方法:
1. **锚定隧道 (Pinned tunnels)**:在这种配置中,用户侧隧道的外部 IP 地址仅通过特定的 Direct Connect VIF 进行路由,如下图所示。这通常发生在用户使用 Direct Connect VIF 接口 IP 地址作为隧道外部 IP 地址时。用户必须在 BGP 会话中向 AWS 通告其 Direct Connect VIF 接口 IP,以确保隧道端点的可达性。尽管 AWS 会自动在所有可用的冗余 Direct Connect VIF 上通告隧道端点 IP (Transit Gateway CIDR),但用户必须配置适当的 BGP 路径选择属性 (如 local preference) 以确保隧道的对称路由。
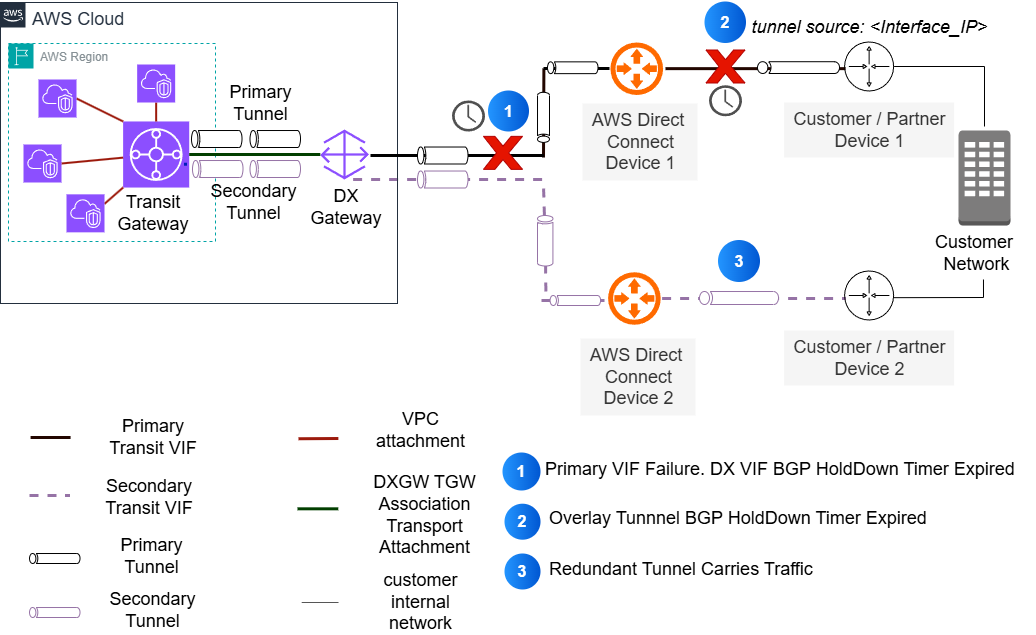
图 2: Direct Connect 上的接口锚定叠加隧道
以下是在运行 IOS-XE 16.1 的 Cisco ASR 1002-HX 设备上配置接口锚定叠加隧道的示例。
```
! DX Interface Configuration
interface TenGigabitEthernet1/0/0.100
description DX-VIF-1
encapsulation dot1q 100
ip address 169.254.100.1 255.255.255.252
no shutdown
! BGP for DX VIF
router bgp 65000
bgp log-neighbor-changes
neighbor 169.254.100.2 remote-as 64512
!
address-family ipv4
! Important: Advertise VIF interface IP for tunnel endpoint reachability
network 169.254.100.1 mask 255.255.255.252
neighbor 169.254.100.2 activate
neighbor 169.254.100.2 route-map SET-LOCAL-PREF in
exit-address-family
! GRE Tunnel Configuration using DX VIF IP
interface Tunnel1
description TGW-Connect-Primary
ip address 172.16.1.1 255.255.255.252
tunnel source 169.254.100.1
tunnel destination 10.0.1.1
tunnel mode gre ip
no shutdown
```
这种将隧道“锚定”到特定连接的方式对故障切换有重要影响。隧道绑定到特定的 Direct Connect 连接,因此在底层连接发生故障时,流量无法立即使用冗余路径。故障切换需要隧道 BGP 会话通过 BGP 计时器超时来检测故障。只有在隧道中断后,流量才会切换。这种方法可能导致更长的故障切换时间。这是因为系统必须等待底层连接故障检测和隧道协议超时,然后数据流量才能切换到冗余路径。
2. **非锚定隧道 (Unpinned tunnels)**:在这种配置中,隧道的外部 IP 地址源自用户路由器上配置的逻辑接口 (如环回接口),如下图所示。AWS 隧道端点 IP (Transit Gateway CIDR) 和用户路由器环回 IP 都可以通过所有可用的 Direct Connect VIF 访问。此设置需要为通告和接收的路由正确配置 BGP 路径属性,以确保对称路由。
对于底层路径的流量工程:
* 在公有 VIF 上:通告环回路由时使用 AS_PATH prepend
* 在私有/中转 VIF 上:通告环回路由时使用 BGP Local Preference communities
更多详细信息,请参阅 Direct Connect 路由策略和 BGP communities [文档](https://docs.aws.amazon.com/directconnect/latest/UserGuide/routing-and-bgp.html) 。
这种方法需要在用户的冗余路由器之间进行路由以交换环回可达性信息,这通常通过 iBGP 配置实现。这种路由是必要的,以便环回地址可以从 AWS 通过冗余的 Direct Connect VIF 访问。
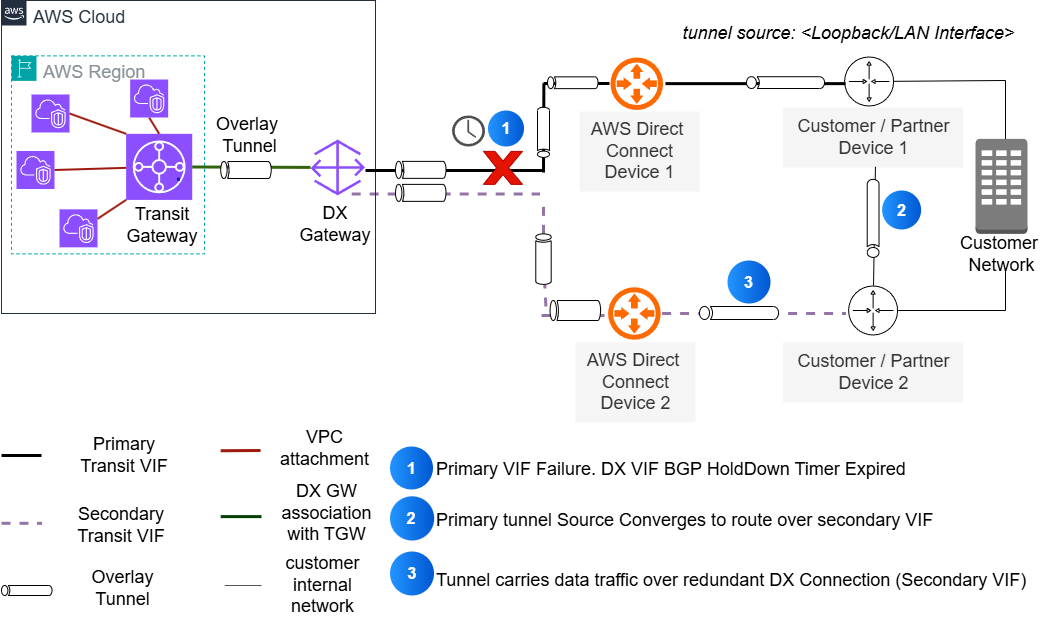
图 3: Direct Connect 上的非锚定叠加隧道
以下是在运行 IOS-XE 16.1 的 Cisco ASR 1002-HX 设备上配置接口环回源叠加隧道的示例。
```
! Loopback Interface Configuration
*interface* Loopback1
description Tunnel-Source-Interface
*ip address* 192.168.1.1 255.255.255.255
no shutdown
! GRE Tunnel Configuration
*interface* Tunnel1
description TGW-Connect
*ip address* 172.16.1.1 255.255.255.252
tunnel source Loopback1 tunnel destination 10.0.1.1
no shutdown
*interface* TenGigabitEthernet1/0/0.100
description DX-VIF-1
encapsulation dot1q 100
*ip address* 169.254.100.1 255.255.255.252
no shutdown
!*BGP* Configuration
router *bgp* 65000
*bgp* log-neighbor-changes
! DX VIF *BGP*
*neighbor* 169.254.100.2 remote-as 64512
!
address-family ipv4
! **Important: Advertise loopback *to* DX VIF *BGP***
*network* 192.168.1.1 mask 255.255.255.255
! **DX VIF *neighbor* - advertise loopback**
*neighbor* 169.254.100.2 activate
*neighbor* 169.254.100.2 route-map SET-LOCAL-PREF *in*
*neighbor* 169.254.100.2 route-map ADVERTISE-LOOPBACK out
exit-address-family
```
## 故障切换时间分析
不同的 AWS 隧道服务使用不同的默认 BGP 计时器设置。我们使用 Transit Gateway Connect 附件来比较锚定和非锚定配置之间的故障切换时间。Transit Gateway Connect 使用的 BGP 计时器与 Direct Connect VIF 不同:10 秒的 keepalive 超时和 30 秒的保持计时器。尽管类似的原则也适用于 Site-to-Site VPN,但其他因素如对等体失效检测 (Dead Peer Detection, DPD) 会影响故障切换时间。有关 DPD 的详细信息,请参阅 [Site-to-Site VPN 文档](https://docs.aws.amazon.com/vpn/latest/s2svpn/VPNTunnels.html) 。
为了有效地优化故障切换时间,您必须了解底层和叠加组件的不同配置如何影响总的故障切换时长。在下一节中,我们将研究 Direct Connect 配置的各种组合 (包括使用和不使用 BFD) 及其对锚定和非锚定隧道架构的影响。
## 故障切换时间比较
下表比较了这些选项:
| **隧道配置类型** | **底层 (DX VIF)** | **叠加 (TGW Connect)** | **总计** | **实施复杂度** | **说明** | **注意事项** |
|---|---|---|---|---|---|---|
| **底层 DX VIF 故障计时器** | **故障时间** |
| 锚定 | 默认 BGP 计时器 | 90 秒 | 30 秒 | ~ 120 秒 | 低 | 故障切换时间 = 底层故障时间 + 叠加隧道 | 恢复缓慢 |
| | 支持的最小 BGP 计时器 | 3 秒 | 30 秒 | ~33 秒 | 低 | | BGP 流量增加 |
| | 支持的最小 BFD 计时器 | 300 毫秒 | 30 秒 | ~30.3 秒 | 中 | | 需要支持 BFD 的硬件 |
| 非锚定 | 默认 BGP 计时器 | 90 秒 | 未触发 | ~90 秒 | 高 | 故障切换时间 = 底层故障时间 | 复杂的内部路由 |
| | 支持的最小 BGP 计时器 | 3 秒 | 未触发 | ~ 3 秒 | 高 | | BGP 流量增加 |
| | 支持的最小 BFD 计时器 | 300 毫秒 | 未触发 | ~ 300 毫秒 | 高 | | 需要 BFD 支持和复杂的内部路由 |
如上表所示,虽然锚定和非锚定配置都可以通过 BFD 实现亚秒级的故障切换时间,但实施复杂度差异显著。为了帮助您在环境中成功实施这些优化,下一节将探讨影响部署的关键考虑因素。
## 实施注意事项
在实施这些故障切换优化技术时,请考虑以下关键方面:
* 性能和硬件
实际的故障切换时间可能因路由器硬件能力和网络复杂性而异。BFD 配置需要兼容的硬件支持以及对 CPU 和内存使用的适当容量规划。请查阅您的网络供应商文档,了解具体的收敛特性和推荐的计时器值。
* 架构限制
尽管 BFD 显著优化了底层故障检测,但它只能在 Direct Connect VIF 上配置,而不能在叠加隧道上配置。请记住,叠加隧道头端故障仍然依赖于隧道的 BGP 计时器。在实施激进的计时器设置时,请注意,如果配置不当,可能会发生 BGP 会话不稳定和非对称路由。
* 实施和验证
成功依赖于有条不紊的实施和持续的验证。从保守的计时器值开始,并根据观察到的性能逐步调整。在进行更改前记录您的基线故障切换时间,并逐步实施优化。这从 BGP 计时器开始,如果支持则启用 BFD,最后实施您选择的隧道配置。
通过 [Direct Connect 故障切换测试](https://docs.aws.amazon.com/directconnect/latest/UserGuide/resiliency_failover.html) 进行定期测试,并通过 [Amazon CloudWatch](https://aws.amazon.com/cloudwatch/) 指标以及设备级别的 BFD 和 BGP 状态监控进行监控,有助于确保您的配置随时间推移保持最佳性能。
## 结论
本文演示了如何优化 AWS Direct Connect 上叠加隧道的故障切换时间。我们的分析表明,与非锚定配置相比,使用默认计时器的锚定隧道配置需要多 33% 的时间来进行故障切换。这主要是由于叠加 BGP 会话超时的依赖性。通过非锚定隧道实施 BFD,您可以将故障切换时间从 90 秒减少到低至 300 毫秒,从而实现 99.7% 的恢复时间改进。对于在 Direct Connect 上实施叠加隧道的用户,我们建议使用非锚定隧道配置,以在故障场景中最小化影响。尽管本文重点关注底层连接故障,但所讨论的原则和配置可以帮助您构建更具弹性的混合网络架构。
有关 Direct Connect 配置和弹性选项的更多信息,请参阅 [Direct Connect 用户指南](https://docs.aws.amazon.com/directconnect/latest/UserGuide/Welcome.html) 。
## 关于作者

### Azeem Ayaz
Azeem 是 AWS 企业支持部门的高级网络专家技术客户经理,专注于战略性企业客户及其复杂的云网络需求。凭借 13 年设计和运营网络及安全基础设施的经验,他擅长打造可扩展的架构,帮助企业最大化其云投资并推动可衡量的业务成果。在加入 AWS 之前,他在 Vodafone、Cisco 和 Juniper 等行业领导者处积累了专业知识。在不设计云解决方案时,Azeem 喜欢玩战略游戏,并与他的伴侣一起探索新的目的地。

### Pavlos Kaimakis
Pavlos 是 AWS 的高级解决方案架构师,帮助客户设计和实施业务关键型解决方案。凭借在产品开发和客户支持方面的丰富经验,他专注于交付能够推动业务价值的可扩展架构。工作之余,Pavlos 是一位热衷旅行的人,喜欢探索新的目的地和文化。
<!-- AI_TASK_END: AI全文翻译 -->