<!-- AI_TASK_START: AI标题翻译 -->
[解决方案] 使用 DNS 防火墙增强 Pinterest 的组织级安全:第一部分
<!-- AI_TASK_END: AI标题翻译 -->
<!-- AI_TASK_START: AI竞争分析 -->
# 解决方案分析
## 解决方案概述
该解决方案详细阐述了 **Pinterest** 如何利用 AWS 服务增强其组织级别的网络安全。核心目标是通过实施 **DNS 防火墙**,将开放的 DNS 查询环境改造为遵循 **最小权限原则** 的 “**围墙花园 (Walled Garden)**” 模型。此方案旨在解决因不受限制的出站(Egress)DNS 查询而引发的各类安全风险,包括 **数据泄露**、**恶意软件与命令控制(C&C)服务器通信** 以及 **僵尸网络协调** 等。方案的技术原理分为两个阶段:首先,通过 AWS 原生服务实现对整个组织内所有 VPC 的 DNS 查询活动进行全面、集中的可见性;其次,对收集到的海量日志数据进行规模化分析,自动生成精细化的域名允许列表,为后续部署防火墙规则奠定基础。该方案尤其适用于拥有众多 AWS 账户和 VPC 的大型企业,特别是那些运行着无需广泛互联网访问权限的后端系统(如离线分析、机器学习平台)的场景。
## 实施步骤
1. **阶段一:集中化 DNS 查询日志收集**
- **1.1. 创建中央日志存储**: 在指定的 **日志归档账户 (Log Archive account)** 中创建 **Amazon S3 存储桶**,用于统一存储来自组织内所有目标 VPC 的 DNS 查询日志。
- **1.2. 配置跨账户访问策略**: 为 S3 存储桶附加策略,授权 Route 53 服务可以将组织内任何成员账户的日志跨账户写入该桶。
- **1.3. 创建并共享日志配置**: 在中心账户创建一个 **Route 53 Resolver 查询日志配置**。随后,利用 **AWS Resource Access Manager (RAM)** 将此配置资源共享给整个 **AWS Organization**。这确保了所有成员账户都能访问到这个标准化的配置。
- **1.4. 关联 VPC**: 在各成员账户中,将需要监控的 VPC 与共享的查询日志配置进行关联。完成后,这些 VPC 内通过 Route 53 Resolver 发起的 DNS 查询日志将自动被发送至中央 S3 存储桶。
2. **阶段二:规模化日志分析与允许列表生成**
- **2.1. 数据准备与拉取**:
- 启动一台多核、高内存的 **Amazon EC2 实例**(如 `r7gd.16xlarge`),并挂载足够容量的 **Amazon EBS** 卷。
- 使用 `AWS CLI` 和 `Unix` 工具(如 `grep`, `xargs`)从 S3 并行拉取日志数据,并按照 `账户ID/VPC ID` 的目录结构进行分区存储,便于后续并行处理。
- **2.2. 并行解压与分析**:
- 利用 `Python` 的并发库进行高效处理。首先,使用 `concurrent.futures.ThreadPoolExecutor` 处理 I/O 密集型的日志文件解压任务。
- 接着,使用 `concurrent.futures.ProcessPoolExecutor` 为每个 VPC 分配一个独立的 Python 进程,并行执行 CPU 密集型的日志分析任务,有效绕过 Python 的全局解释器锁(GIL)限制。
- **2.3. 规则提取与优化**:
- 在分析过程中,将子域名替换为通配符(`*`)以减小规则集的规模并简化维护。
- 追踪 `CNAME` 记录链,确保将重定向链中的所有域名都加入允许列表。
- 精确到 **查询类型** (Query Type),即为同一个域名根据实际请求的记录类型(如 `A`, `AAAA`, `MX`)生成不同的规则,而非笼统地允许所有查询类型。
- **2.4. 聚合与输出**:
- 分析流程首先为每个 VPC 生成一个独立的 JSON 文件,其中包含域名到其对应查询类型的映射。
- 随后,对所有 JSON 文件进行聚合分析,生成三个层级的 YAML 格式允许列表:
- **组织级通用列表**: 跨绝大多数账户的共同域名。
- **账户级通用列表**: 在单个账户内多数 VPC 中共同出现的域名。
- **VPC 级特定列表**: 仅在特定 VPC 中出现的独有域名。
## 方案客户价值
- **增强安全防御能力**: 通过实施基于允许列表的 DNS 防火墙,遵循 **最小权限原则**,极大降低了恶意软件通过 DNS 通道进行通信或数据泄露的风险。
- **实现全组织网络可见性**: 方案提供了对整个 AWS Organization 内 DNS 活动的 **集中化、全面的可见性**,为安全审计、威胁发现和事件响应提供了关键数据支持。
- **自动化与可扩展的规则生成**: 建立了一套可扩展的日志分析管道,能够利用 `Python` 和标准工具自动化处理海量日志数据,高效地为复杂的多账户环境生成和维护精细化的防火墙规则。
- **精细化访问控制**: 实现了超越简单域名封堵的控制能力,能够基于 **DNS 查询类型** 进行授权,从而实施更为精准和严格的安全策略。
## 涉及的相关产品
- **AWS Organizations**: 用于对多个 AWS 账户进行集中治理与管理。
- **Amazon Route 53 Resolver query logging**: 捕获所有从 VPC 发往 Route 53 Resolver 的 DNS 查询,是数据收集的核心功能。
- **AWS Resource Access Manager (RAM)**: 用于在组织内安全、便捷地共享 Route 53 Resolver 查询日志配置等资源。
- **Amazon S3**: 作为高可用、可扩展的中央日志存储库。
- **Amazon EC2**: 提供用于大规模日志分析的按需计算能力。
- **Amazon EBS**: 为 EC2 实例提供高性能、持久化的块存储,用于存放和处理日志数据。
- **Amazon Route 53 Resolver DNS Firewall**: (在系列第二部分详述)执行 DNS 过滤规则的核心安全服务。
## 技术评估
- **优势**:
- **原生服务深度集成**: 方案完全基于 AWS 原生服务构建,确保了各组件间的无缝集成、高可靠性及统一的管理体验。
- **高可扩展性设计**: 从使用 AWS RAM 进行配置的集中分发,到采用多进程并行处理海量日志,整个架构都为大型企业级的规模化部署进行了优化。
- **灵活性与可定制性**: 日志分析流程采用 `Python` 和标准 `Unix` 工具,虽然需要一定的开发投入,但提供了极高的灵活性,企业可以根据自身需求深度定制分析逻辑和规则生成策略。
- **可能的限制与挑战**:
- **实施复杂度**: 方案的日志分析部分需要较强的基础设施即代码(IaC)和 `Python` 编程能力,对实施团队的技术栈有一定要求。
- **单机分析瓶颈**: 对于 PB 级别的超大规模日志,文中推荐的单机 EC2 分析模式可能会遇到性能瓶颈。原文也预见性地提出了替代方案,表明该方案有其最佳适用范围。
- **规则的动态维护**: 生成的允许列表是基于特定时间窗口的快照。在业务快速迭代的环境中,必须建立一个持续的流程来监控新的 DNS 需求、更新允许列表并重新部署规则,以避免误拦截导致的业务中断。
## 其他信息
- **性能优化建议**:
- **存储 I/O**: 建议在用于分析的 EC2 实例上配置 **RAID 0** 磁盘阵列,以提高本地存储的读写性能,加速日志处理速度。
- **大数据备选方案**:
- **交互式查询**: 对于海量日志,可使用 **Amazon Athena** 直接对存储在 S3 上的日志运行 SQL 查询。
- **分布式处理**: 可采用 **Apache Spark**(如通过 Amazon EMR 或 AWS Glue)等大数据处理框架进行更强大的分布式集群分析。
<!-- AI_TASK_END: AI竞争分析 -->
<!-- AI_TASK_START: AI全文翻译 -->
# 使用 DNS 防火墙增强 Pinterest 的组织安全性:第一部分
**原始链接:** [https://aws.amazon.com/blogs/networking-and-content-delivery/enhancing-pinterests-organizational-security-with-a-dns-firewall-part-1/](https://aws.amazon.com/blogs/networking-and-content-delivery/enhancing-pinterests-organizational-security-with-a-dns-firewall-part-1/)
**发布时间:** 2025-08-18
**厂商:** AWS
**类型:** BLOG
---
***本文由 Pinterest 基础设施安全团队的高级安全软件工程师 Ali Yousefi 撰写***
# 引言
随着越来越多的组织转向云端,网络安全已成为云安全中日益重要的焦点领域。组织可以通过加强其网络安全,采取积极措施保护自身及其数据免受各种威胁。强化出口控制 (egress controls) 是实施这些安全措施的一种方法,有助于组织降低数据泄露 (data exfiltration)、恶意软件通信、僵尸网络协调和其他安全威胁的风险。
域名系统 (DNS) 是网络协议栈中可以设置出口控制的一个层面。通过获取其网络内 DNS 活动的可见性并部署 DNS 防火墙 (DNS firewall),组织可以缓解许多与 DNS 相关的潜在威胁。在这个由两部分组成的博客系列的第 1 部分中,我们演示了 Pinterest 如何获得对其整个 Amazon Web Services ([AWS Organization](https://aws.amazon.com/organizations/) ) 中系统发出的 DNS 查询的可见性,并使用 Python 大规模分析这些 DNS 查询日志,以构建一套允许列表 (allowlist) DNS 防火墙规则。在第 2 部分中,我们将展示如何使用这些允许列表,通过 [AWS Firewall Manager](https://aws.amazon.com/firewall-manager/) 和 [Amazon Route 53 Resolver DNS Firewall](https://aws.amazon.com/route53/resolver-dns-firewall/) 部署一个覆盖整个 AWS Organization 的 DNS 防火墙。
# 背景
通常,组织的网络最初都具有广泛开放的 DNS 查询能力。尽管这对于某些用例 (例如爬虫) 可能是必要的,但大多数工作负载并不需要这种无限制的 DNS 查询。对于主要用于分析 (例如 OLAP 系统) 和机器学习 (ML) 的离线系统尤其如此。
从广泛开放的 DNS 访问开始,为我们实施最小权限原则 (principle of least privilege) ([https://en.wikipedia.org/wiki/Principle_of_least_privilege](https://en.wikipedia.org/wiki/Principle_of_least_privilege) ) 提供了机会:仅授予系统所需的权限,并默认拒绝所有其他权限。在 DNS 防火墙的背景下,这意味着只允许对网络中运行的工作负载所必需的域和查询类型进行 DNS 查询,同时默认拒绝所有其他 DNS 查询。这种策略被称为围墙花园 (Walled Garden)。
要在 AWS 上构建 DNS 围墙花园,第一步是获取源自该组织 VPC 的 DNS 流量的可见性。这种可见性使我们能够创建允许列表规则,防火墙通过这些规则允许授权的 DNS 解析请求传递给 [Amazon Route 53 Resolver](https://aws.amazon.com/route53/resolver/) ,同时阻止所有其他使用 Route 53 Resolver 的 DNS 解析。
# 解决方案概述
该解决方案使用以下 AWS 服务:
- Organizations: 实现对多个 AWS 账户的集中管理和治理
- [AWS Resource Access Manager (AWS RAM)](https://aws.amazon.com/ram/) : 便于跨账户共享 AWS 资源
- [Amazon Route 53 Resolver 查询日志记录 (query logging)](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/resolver-query-logs.html) : [Amazon Route 53](https://aws.amazon.com/route53/) 中的一项功能,允许记录从 VPC 发往 Route 53 Resolver 的 DNS 查询
- [Amazon Simple Storage Service (Amazon S3)](https://aws.amazon.com/s3/) : 一种对象存储服务,提供可扩展性、高可用性、安全性和性能
- [Amazon Elastic Compute Cloud (Amazon EC2)](https://aws.amazon.com/ec2/) : 提供在 AWS 中创建和管理可调整计算容量的能力
- [Amazon Elastic Block Store (Amazon EBS)](https://aws.amazon.com/ebs/) : 提供可附加到 EC2 实例的高性能块存储
## 阶段 1:设置 Route 53 Resolver 查询日志
第一步是在整个 AWS Organization 的 VPC 中部署并关联一个标准化的 Route 53 Resolver 查询日志配置,如图 1 所示。此配置为我们提供了关于 AWS Organization 中工作负载所发出的 DNS 查询以及收到的 DNS 响应的全面洞察。建议使用基础设施即代码 (IaC) ([https://aws.amazon.com/what-is/iac/](https://aws.amazon.com/what-is/iac/) ) 工具 (例如 [Terraform](https://developer.hashicorp.com/terraform/) 或 [AWS CloudFormation](https://aws.amazon.com/cloudformation/) ) 来部署云基础设施。
### 前提条件
阶段 1 需要满足以下前提条件:
- [必须已设置 AWS Organizations](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_getting-started.html)
- [必须启用 AWS RAM 并配置其与 AWS Organizations 的集成](https://docs.aws.amazon.com/organizations/latest/userguide/services-that-can-integrate-ram.html)
- 访问具有以下权限的 [AWS Identity and Access Management (IAM)](https://aws.amazon.com/iam/) 主体:
- 创建 Route 53 Resolver 查询日志配置
- 创建 S3 存储桶并附加存储桶策略
- 创建 AWS RAM 资源共享、资源关联和主体关联
- 在每个 AWS Organization 成员账户中创建 Route 53 Resolver 查询日志配置关联
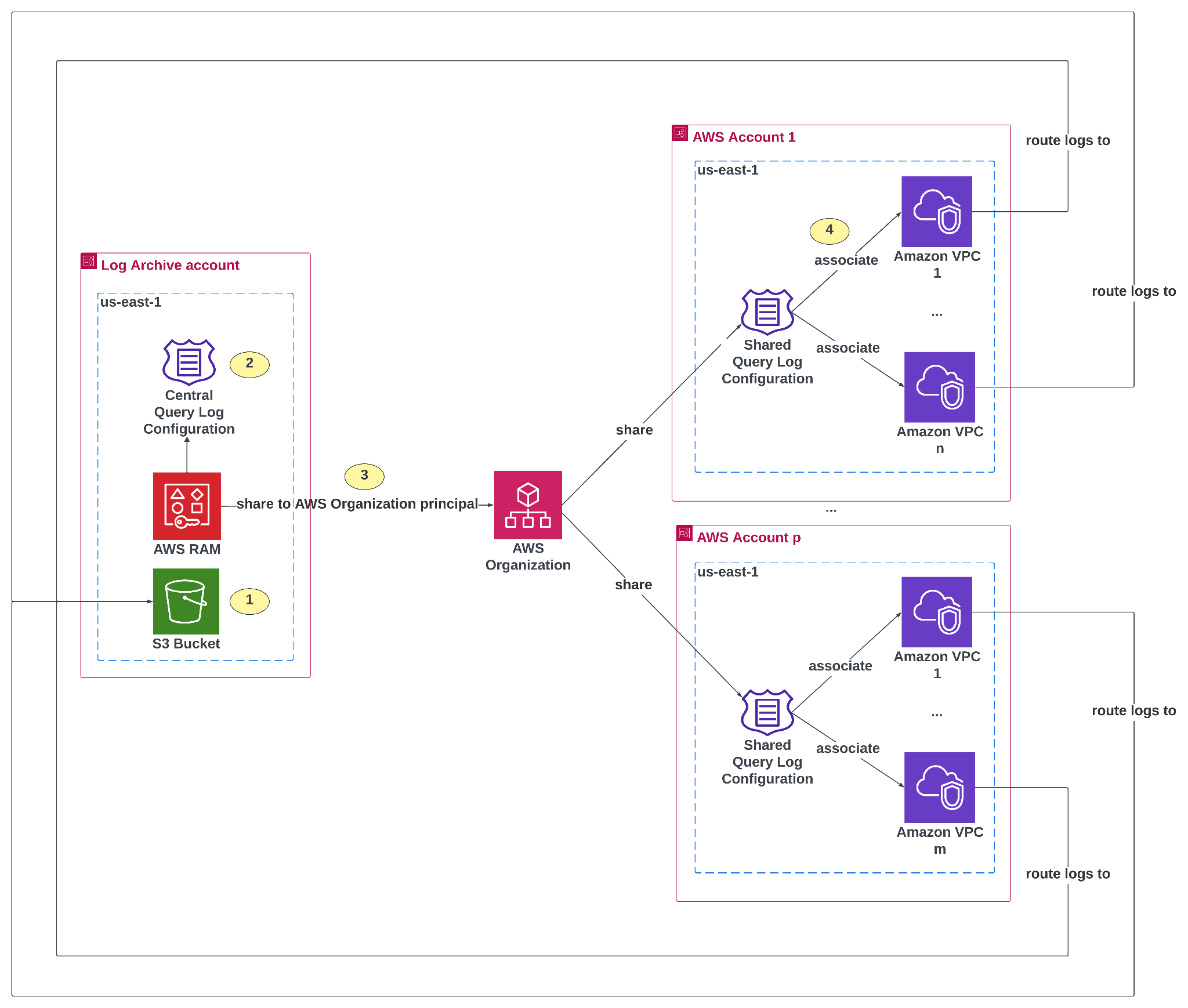
*图 1: 在整个 AWS Organization 中启用 Route 53 Resolver 查询日志*
*替代文本: 显示跨多个 AWS 账户集中进行 Amazon VPC DNS 查询日志记录的架构图。左侧,“日志归档账户”包含三个组件:一个用于日志存储的 Amazon S3 存储桶、一个中央查询日志配置,以及用于共享资源的 AWS Resource Access Manager (RAM)。中央查询日志配置与 AWS Organization 共享 (步骤 3)。右侧,多个 AWS 账户 (账户 1 到账户 p) 各自拥有一个或多个 Amazon VPC。每个 VPC 都与共享的查询日志配置相关联,从而允许日志路由回日志归档账户中的中央 S3 存储桶。箭头说明了日志从所有账户中的 VPC 流向中心化存储桶的过程。*
### 实施
1. 需要一个中央 S3 存储桶来存储来自目标 VPC 的查询日志。我们建议在您组织的日志归档账户 (Log Archive account) ([https://docs.aws.amazon.com/prescriptive-guidance/latest/security-reference-architecture/log-archive.html](https://docs.aws.amazon.com/prescriptive-guidance/latest/security-reference-architecture/log-archive.html) ) 中创建此存储桶。必须附加此[文档](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/resolver-query-logs-choosing-target-resource.html) 中指定的存储桶策略,以允许来自您 AWS Organization 内所有账户的跨账户日志交付。如果用于在本博文第 2 阶段检索数据的 IAM 主体位于不同于存储桶所有者账户的账户中,则存储桶策略还必须授予该 IAM 主体读取权限。
2. 在单个账户 (例如日志归档账户) 中定义一个中央 Route 53 Resolver 查询日志配置。
3. 使用 AWS RAM 与 AWS Organization 主体共享中央查询日志配置。因此,AWS Organization 中的每个账户都会收到此标准化配置。
4. 共享的查询日志配置必须与您的目标 VPC 相关联。
## 阶段 2:使用 Python 大规模分析 DNS 查询日志
成功配置查询日志发送到 Amazon S3 后,我们可以分析它们来构建初始的围墙花园防火墙允许列表。请留出适当的时间让日志累积,以捕获系统发出的完整 DNS 查询集。日志分析管道包括以下步骤:
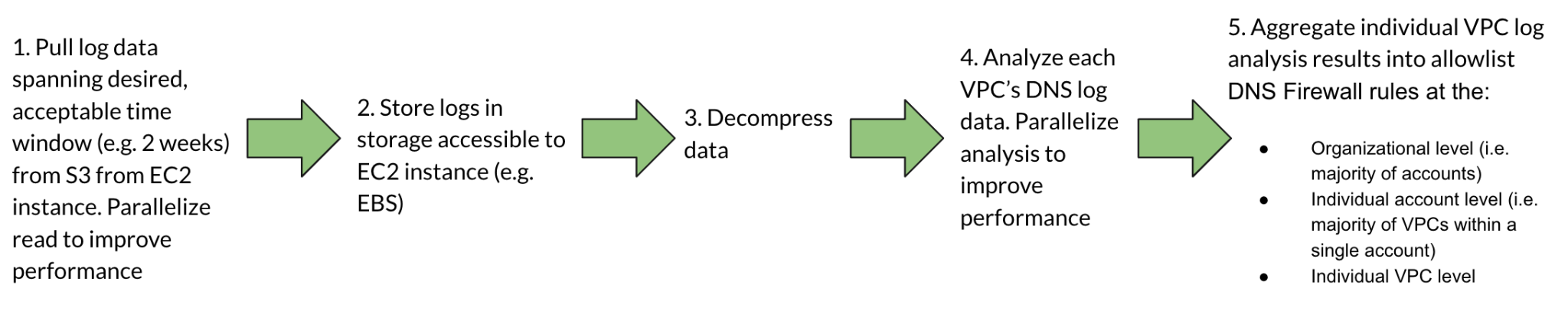
*图 2: Route 53 Resolver 查询日志分析管道*
*替代文本: 一个五步图,说明如何分析 VPC DNS 日志并创建 DNS 防火墙允许列表规则:将日志从 S3 拉取到 EC2,存储在可访问的存储中,解压缩,通过并行处理对每个 VPC 进行分析,并将结果聚合为组织、账户和 VPC 级别的 DNS 防火墙允许列表规则。*
### 前提条件
阶段 2 需要满足以下前提条件:
- 一个多核、基于 Linux 的 EC2 实例。在 Pinterest,我们使用了一个 [r7gd.16xlarge 内存优化实例](https://aws.amazon.com/ec2/instance-types/) 进行数据分析,以通过并行化技术利用机器的多个核心和相对较高的内存容量。这使我们能够高效地使用 Python 进行分析。
- 一个附加到该实例的基于网络的存储系统 (例如 Amazon EBS),具有足够的存储容量来存储压缩和未压缩的数据。
- 实例上安装了以下工具:
- [AWS Command Line Interface (AWS CLI)](https://aws.amazon.com/cli/) 版本 >= 1.27.147
- [Python 3](https://www.python.org/downloads/) 版本 >= 3.8.16
- [grep](https://www.gnu.org/software/grep/)
- [xargs](https://en.wikipedia.org/wiki/Xargs)
- [uniq](https://en.wikipedia.org/wiki/Uniq)
- [sort](https://en.wikipedia.org/wiki/Sort_\(Unix\))
- [awk](https://en.wikipedia.org/wiki/AWK)
- EC2 实例上的 AWS CLI 可用的 IAM 凭证,具有对中心化 S3 存储桶的读取访问权限。
### 实施
我们可以使用前面提到的 AWS CLI 和 Unix 工具来完成几项任务:汇总数据大小、并行化 Amazon S3 读取、按账户 ID、VPC ID 和时间窗口筛选日志 (图 3),并将日志存储在实例可访问的基于网络的存储系统 (例如 Amazon EBS) 上。对于下游分析,将日志以分区方式存储在文件系统上是有益的,首先按账户 ID 组织,然后按 VPC ID 组织 (图 3)。这种组织方式可以实现并行解压缩和分析,使我们能够用 Python 高效地构建允许列表。图 3 显示了导入数据的推荐存储布局:
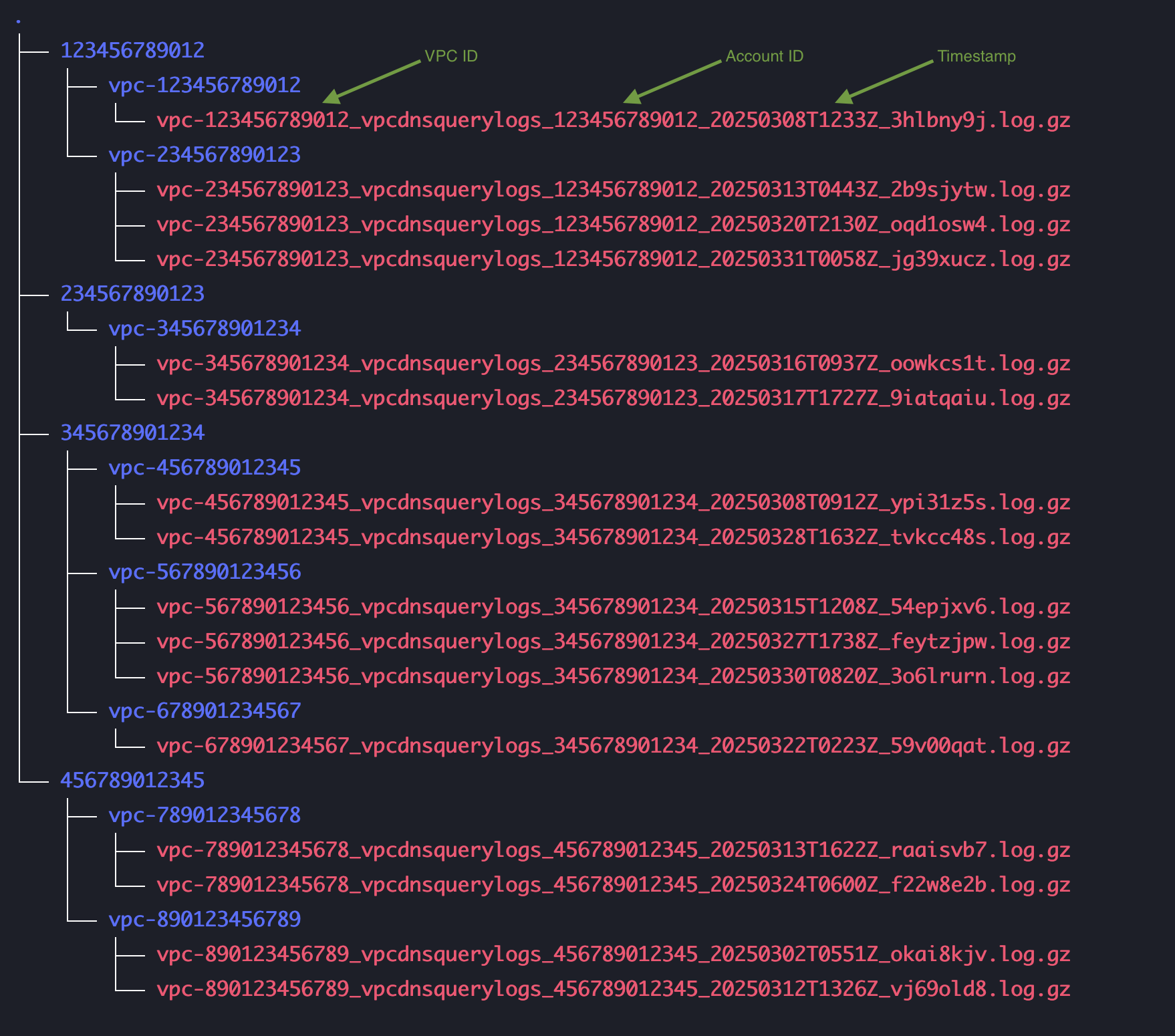
*图 3: 用于下游分析的日志存储布局*
*替代文本: 显示按 AWS 账户 ID 和 VPC ID 组织的 Amazon VPC DNS 查询日志文件的树状结构视图。每个文件夹代表一个 AWS 账户 ID,其中包含各个 VPC ID 的子文件夹。在每个 VPC 文件夹内有多个日志文件,其命名格式为:vpc- <VPC-ID>_vpcdnsquerylogs_<Account-ID>_<Timestamp>_<RandomString>.log.gz。文件名上方的绿色标签指示了代表 VPC ID、账户 ID 和时间戳的部分。*
使用自定义的 Python 工具,将日志数据解压缩到另一个目录,同时保持图 3 所示的相同存储布局结构。实施并发以解压缩所有数据进行分析。文件解压缩通常是 I/O 密集型 (I/O-bound) 的,因此您应该首先使用 `concurrent.futures.ThreadPoolExecutor` ([https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ThreadPoolExecutor](https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ThreadPoolExecutor) ) 来处理流程:从磁盘读取数据、解压缩数据,然后使用多个并发的 Python 线程将解压缩后的数据写回磁盘。如果您需要提高性能,并怀疑 Python 全局解释器锁 (GIL) ([https://wiki.python.org/moin/GlobalInterpreterLock](https://wiki.python.org/moin/GlobalInterpreterLock) ) 正在造成瓶颈,那么可以考虑切换到 `concurrent.futures.ProcessPoolExecutor` ([https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ProcessPoolExecutor](https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ProcessPoolExecutor) ) 来跨多个 vCPU 和 Python 进程并行化操作。
为了在我们实例中运行的多个 Python 进程之间并行化日志分析,我们可以使用 `ProcessPoolExecutor` ([https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ProcessPoolExecutor](https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ProcessPoolExecutor) ) 类为每个 VPC 创建一个独立的子进程,该子进程读取并处理其分配的 VPC 的原始日志数据文件。此流程在不同阶段涉及 I/O 密集型和 CPU 密集型 (CPU-bound) 操作。从磁盘将日志数据加载到内存的初始阶段是 I/O 密集型的。当数据在内存中时,任务就变成了 CPU 密集型,因为我们要处理日志条目来构建允许列表。使用 `ProcessPoolExecutor` 按 VPC 并行化分析,使我们能够绕过 Python GIL 的限制,该限制通常会阻止由 `ThreadPoolExecutor` 类创建的并发运行的 Python 线程执行并行的 CPU 密集型工作,从而提高分析性能。由 `ProcessPoolExecutor` 创建的每个工作进程都可以在我们的多核实例上与其他工作进程并行地将其分配的 VPC 日志数据读入内存并进行处理。
将与特定域关联的所有子域都加入允许列表有几个好处:可以减小域列表的大小、简化允许列表的维护,并提高开发人员的生产力。这可以通过在适用的情况下,将日志条目中 `query_name` 字段的子域部分替换为通配符 `*` 来实现。当对一个查询的 DNS 响应 (在日志条目的 `answers` 字段中找到) 包含别名其他主机名的记录 (例如 CNAME 记录) 时,我们必须将完整的重定向链中找到的所有域名都加入允许列表,才能将最初查询的域加入允许列表。
域名应根据其观察到的查询类型加入允许列表,而不是为每个域允许所有查询类型。这种方法更严格地遵循了最小权限原则。每个单独的 VPC 分析都应生成一个 JSON 文件,该文件将查询的域名映射到其对应的请求查询类型。图 4 显示了分析特定 VPC 的 DNS 查询日志后生成的示例 JSON 文件:
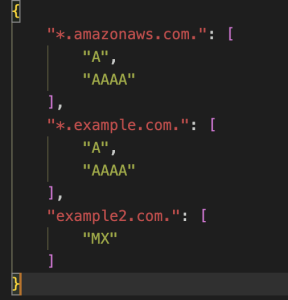
*图 4: 单个 VPC 分析的输出文件。包含域名到特定 VPC 查询日志中为每个域名请求的查询类型的映射。*
*替代文本: 一个 JSON 配置片段,定义了特定域允许的 DNS 记录类型。它包括三个条目:1/ “*.amazonaws.com.”,记录类型为 “A” 和 “AAAA”;2/”*.example.com.”,记录类型为 “A” 和 “AAAA”;3/”example2.com.”,记录类型为 “MX”。*
生成所有单独的 JSON 文件后,进行一次聚合分析,将每个文件作为输入进行处理。此聚合分析应识别出单个账户内的常见 DNS 查询 (发生在单个账户内的大多数 VPC 中) 以及在大多数被分析账户之间共享的常见 DNS 查询。对于跨账户识别出的常见 DNS 查询,您的聚合分析可以输出一个如图 5 所示的 YAML 文件:
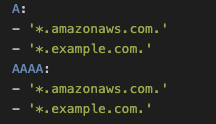
*图 5: 粗粒度的“允许所有账户”的允许列表*
*替代文本: 一个 YAML 配置片段,定义了特定域允许的 DNS 记录类型。A 记录类型允许 *.amazonaws.com. 和 *.example.com.,AAAA 记录类型也允许 *.amazonaws.com. 和 *.example.com.。*
您的分析还应为在每个单独账户内观察到的常见 DNS 查询输出一个类似的 YAML 文件。此输出的示例如图 6 所示:
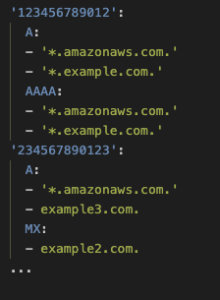
*图 6: 单个账户内常见的 DNS 查询*
*替代文本: 一个 YAML 配置片段,将 AWS 账户 ID 映射到允许特定域的 DNS 记录类型。对于账户 123456789012,允许 *.amazonaws.com. 和 *.example.com. 的 A 和 AAAA 记录类型。对于账户 234567890123,A 记录类型允许 *.amazonaws.com. 和 example3.com.,MX 记录类型允许 example2.com.。*
您的分析还应识别并输出特定于 VPC 的、而不是在账户内或跨多个账户常见的 DNS 查询。此输出的示例如图 7 所示:
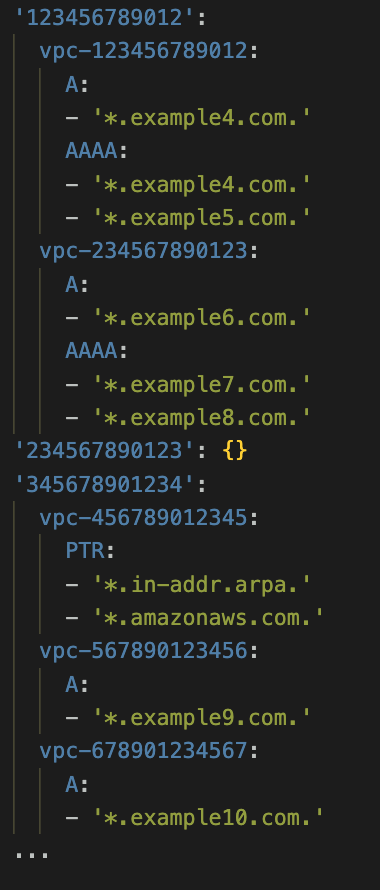
*图 7: 从每个 VPC 观察到的唯一 DNS 查询*
*替代文本: 该 YAML 配置片段定义了跨多个 AWS 账户 ID 的特定 VPC 允许的 DNS 记录类型。在账户 123456789012 中,vpc-123456789012 允许域 *.example4.com. 和 *.example5.com. 的 A 和 AAAA 记录类型,而 vpc-234567890123 允许 *.example6.com. 的 A 记录以及 *.example7.com. 和 *.example8.com. 的 AAAA 记录。账户 234567890123 未配置规则。在账户 345678901234 中,vpc-456789012345 配置为允许反向查找域 *.in-addr.arpa. 和 AWS 域 *.amazonaws.com. 的 PTR 记录,vpc-567890123456 允许 *.example9.com. 的 A 记录,而 vpc-678901234567 允许 *.example10.com. 的 A 记录。*
使用最后两个输出文件为每个特定的 VPC 构建您的 Route 53 Resolver DNS Firewall 自定义规则组规则。此过程将在本系列的第 2 部分中详细解释。
# 注意事项
- 实施 [RAID 0](https://en.wikipedia.org/wiki/Standard_RAID_levels) 配置以大规模分析日志,因为这能够实现本地存储相对更大量的数据。
- 考虑使用替代工具和服务进行大规模数据分析和日志处理:
- [Amazon Athena](https://aws.amazon.com/athena/) 用于对中心化日志数据运行 SQL 查询
- [Apache Spark](https://spark.apache.org/) (例如 [PySpark](https://spark.apache.org/docs/latest/api/python/index.html)) 用于执行集群级分布式数据分析和构建防火墙规则
对于非常大的数据量,建议使用这些类型的服务和大数据处理框架,而不是本地处理。
# 结论
在这篇文章中,我们演示了组织如何增强其网络可见性能力。我们展示了如何使用 Amazon Route 53 Resolver 查询日志记录和 AWS RAM 来深入了解我们 AWS Organization 中发生的 DNS 活动。此外,我们还演示了如何使用标准的 Unix 工具和 Python 构建一个日志分析管道,以大规模读取和分析 DNS 流量,从而创建粗粒度和细粒度的 DNS 防火墙规则允许列表。在本博客系列的两部分的 [第 2 部分](https://aws.amazon.com/blogs/networking-and-content-delivery/enhancing-pinterests-organizational-security-with-a-dns-firewall-part-2/) 中,我们将演示如何使用分析结果来部署一个灵活、安全、经济高效且稳健的 DNS 防火墙。该解决方案使用 Firewall Manager 和 Route 53 Resolver DNS Firewall 来实施 DNS 控制。
---
### 关于作者

### Ali Yousefi
Ali Yousefi 是 Pinterest 的一名高级软件工程师,专注于网络安全、大数据、AI/ML 和云架构。在他的职位上,他领导设计和实施影响各种系统的大规模、安全、多账户的 AWS 架构。他与组织内的各个团队合作解决复杂的技术问题。Ali 在数据、分析、AI、数字广告和金融服务等多个行业拥有丰富的工作经验。
<!-- AI_TASK_END: AI全文翻译 -->