<!-- AI_TASK_START: AI标题翻译 -->
[解决方案] 如何使用 AWS WAF 管理 AI 机器人并增强安全
<!-- AI_TASK_END: AI标题翻译 -->
<!-- AI_TASK_START: AI竞争分析 -->
# 基于 AWS WAF 管理 AI 机器人的解决方案分析
## 解决方案概述
本文档详细描述了使用 AWS WAF 检测和管理 AI 机器人的方法,旨在解决 AI 机器人带来的安全挑战。核心内容包括 **AI 机器人分类**(如 AI 抓取器、AI 工具和 AI 代理)、问题识别(如性能下降和数据滥用)以及基于 AWS WAF 的防护机制。
该解决方案针对互联网应用的安全需求,适用于 **Web 应用托管场景**,如使用 Amazon CloudFront 或 Application Load Balancer (ALB) 的环境。背景是 AI 机器人的快速发展导致的数据盗取、服务器负载增加和用户体验下降问题。技术原理基于 **AWS WAF 的规则组**(如 Bot Control 规则组)和 **流量监测机制**,通过签名验证、指纹识别和速率限制来识别并管理机器人流量。
## 实施步骤
1. **准备阶段**:启用 AWS WAF 保护,首先使用 AWS Shield 网络安全总监可视化威胁景观,识别未受保护的资源。然后,通过一键式集成为 CloudFront 或 ALB 创建初始安全配置,包括保护包或 Web ACL,以防御常见威胁。
2. **监测 AI 机器人活动**:添加 AWS WAF Bot Control 规则组(Common Inspection 级别),初始设置为 Count 模式,监测流量模式。配置最新版本(如 3.2),分析 CategoryAI 规则检测的 AI 机器人请求。运行数日后,通过 AWS WAF 和 AWS Shield 控制台查看仪表板数据,评估机器人活动规模。
3. **管理机器人问题**:
- 使用 robots.txt 文件控制合规机器人:例如,针对 Amazonbot 设置 Disallow 和 Allow 指令,阻止访问特定路径。
- 通过 AWS WAF 规则处理顽固机器人:移除规则的 Count 模式,转为 Block;添加自定义规则基于标签(如 awswaf:managed:aws:bot-control:bot)阻塞特定机器人;应用速率限制、挑战动作(如 AWS WAF Challenge)和 CAPTCHA 以减缓或捕获逃避性机器人。
- 针对代理型机器人,使用 Targeted Inspection 级别结合指纹技术检测人类模拟行为,并考虑身份验证(如生物识别)。
4. **优化和迭代**:基于监测数据调整规则阈值,确保合法流量不受影响,并参考 AWS WAF 最佳实践文档持续更新配置。
## 方案客户价值
- **数据保护和知识产权维护**:防止未经授权的数据用于训练 AI 模型,避免内容被竞争服务利用,相比传统方案(如手动监控),可显著减少知识产权风险。
- **性能提升和成本优化**:通过阻塞高流量机器人,降低服务器负载和数据传输出 (DTO) 费用,实现 _性能改善_ 和资源浪费减少;例如,robots.txt 和 AWS WAF 组合可有效缓解高峰期服务中断,与未保护方案相比,减少计算资源消耗。
- **用户体验和品牌声誉提升**:抑制恶意机器人互动,保护合法用户流量,避免流量竞争(如抢购库存),从而维护用户信任;相较竞品(如其他云提供商的 WAF),AWS WAF 的自适应规则提供更精细的流量管理。
## 涉及的相关产品
- **AWS WAF**:核心防护工具,用于检测和阻塞 AI 机器人,提供 Bot Control 规则组和速率限制功能。
- **AWS Shield**:辅助可视化威胁景观,支持网络安全总监功能,帮助识别未保护资源。
- **Amazon CloudFront**:内容分发网络,支持一键式 WAF 集成,保护托管应用。
- **Application Load Balancer (ALB)**:负载均衡器,提供一键式 WAF 集成,优化流量管理和机器人防护。
- **Security Automations for AWS WAF**:包含蜜罐端点,用于捕获逃避性机器人,增强防护效果。
## 技术评估
- **先进性**:解决方案采用先进的 **指纹识别和标签机制**,如 Bot Control 规则组的 CategoryAI 规则,能有效检测演进中的 AI 机器人,领先于传统 WAF 的简单签名验证,适应 AI 时代的安全趋势。
- **可行性**:实施门槛低,支持一键集成和监控模式,适用于中小型应用,但需依赖 AWS 环境,迁移成本较高。
- **适用范围**:适合高流量 Web 应用场景,如电商和内容平台,但对高度逃避性机器人(如使用 VM 模拟人类行为)可能需结合多层防护;优势包括灵活的规则自定义和实时仪表板,限制在于部分机器人可能忽略 robots.txt,导致需额外 AWS WAF 干预。
- **优势和局限性**:优势是集成性强,能量化减少流量滥用;局限性包括潜在的假阳性风险,需要持续优化规则以平衡安全和可用性。
<!-- AI_TASK_END: AI竞争分析 -->
<!-- AI_TASK_START: AI全文翻译 -->
# 如何使用 AWS WAF 管理 AI 机器人 (AI bots) 并提升安全性
**原始链接:** [https://aws.amazon.com/blogs/networking-and-content-delivery/how-to-manage-ai-bots-with-aws-waf-and-enhance-security/](https://aws.amazon.com/blogs/networking-and-content-delivery/how-to-manage-ai-bots-with-aws-waf-and-enhance-security/)
**发布时间:** 2025-08-01
**厂商:** AWS
**类型:** 博客
---
# 引言
第一款网络爬虫于 1993 年创建,用于测量网络规模,如今它们已演变为由代理 AI 驱动的现代机器人 (bots)。当今的互联网越来越被自动化 AI 机器人 (AI bots) 所填充和主导,它们与应用互动以支持 AI 相关任务。
我们将 AI 机器人 (AI bots) 分类为三种类型:
1. **AI 抓取器 (AI scrapers)**,它们系统地从您的应用收集数据以训练 AI 模型。
2. **AI 工具 (AI tools)**,它们使用 [Function calling](https://docs.aws.amazon.com/bedrock/latest/userguide/tool-use.html) 从您的应用中提取数据,并在 AI 应用中呈现。
3. **AI 代理 (AI agents)**,它们可以自主导航并动态与您的应用互动,以执行复杂任务。
尽管有些 AI 机器人 (AI bots) 提供有价值的服務,如自动化繁琐任务,但有些恶意机器人 (bots) 可能给 Web 应用所有者和运营商带来重大挑战。恶意机器人 (bots) 可能会用过量流量淹没服务器,导致性能下降甚至中断。如果不加以控制,这些机器人 (bots) 不仅会损害安全性,还可能侵蚀用户信任并损害品牌声誉。
在本帖子中,我们探讨 AI 机器人 (AI bots) 引起的不同问题,并学习使用 [Amazon Web Services (AWS) WAF](https://aws.amazon.com/waf/) 检测和管理 AI 机器人 (AI bots)。
# 先决条件
本帖子聚焦于 AWS WAF 作为观察和管理针对您的应用的 AI 机器人 (AI bots) 活动的防线。如果您尚未启用 AWS WAF 保护,则可以通过使用 [AWS Shield 网络安全总监 (Network Security Director)](https://docs.aws.amazon.com/waf/latest/developerguide/nsd-chapter.html) 可视化威胁格局来开始。它帮助您识别未受 AWS WAF 保护的资源。
然后,您可以使用一键式安全集成创建初始安全态势。它会自动创建一个 [保护包或 Web ACL](https://docs.aws.amazon.com/waf/latest/developerguide/how-aws-waf-works.html),其中包含规则,以保护您的应用免受大多数常见威胁。请参考以下内容:
1. 如果您使用 [Amazon CloudFront](https://aws.amazon.com/cloudfront/) 托管应用,则使用 [CloudFront 一键式 AWS WAF 集成](https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/WAF-one-click.html) 启用保护。
2. 如果您使用 [Application Load Balancer (ALB)](https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html) 托管应用,则使用 [ALB 一键式 AWS WAF 集成](https://docs.aws.amazon.com/elasticloadbalancing/latest/application/application-load-balancers.html#load-balancer-waf) 启用保护。
# AI 机器人 (AI bots) 引起的问题
机器人 (bots) 不是网络上的新威胁。然而,大型语言模型 (Large Language Models, LLMs) 的数据需求以及 AI 代理 (AI agents) 启用的新互动模式,使得机器人 (bots) 行为在许多应用中变得更加棘手。Web 应用可能面临以下由 AI 机器人 (AI bots) 引起的问题:
1. **使用专有数据训练模型**:未经授权使用您组织的数据可能会在用于训练 AI 模型时引发知识产权问题。例如,您的内容可能被用于创建潜在竞争服务,而不提供补偿,并稀释您内容的独特市场价值。
2. **性能低下和高成本**:积极抓取您应用内容的 AI 机器人 (AI bots) 可能会产生压倒性流量,导致合法用户性能下降。这还可能产生数据传输出 (DTO) 费用,浪费计算资源,并在高峰抓取期导致潜在服务中断。
3. **不需要人工参与的自动化/代理行为**:AI 机器人 (AI bots) 可以自动与您的应用互动,从而抢走宝贵的人工流量,因为 AI 可以总结其发现。AI 机器人 (AI bots) 还可能与合法的人类流量竞争,以完成高价值、时间敏感的工作流程,如购买有限库存。这些机器人 (bots) 通常使用以下技术与您的应用互动:
- **Function calling 和 AI 搜索**:AI 应用使用工具搜索并直接从您的应用发出一次性数据请求。
- **浏览器自动化框架互动**:AI 代理 (AI agents) 如 Amazon Nova Act 使用 Playwright 控制真实浏览器。它们可以完成多步骤任务,并以类似人类的方式与应用互动。这些代理 (agents) 可以执行 JavaScript 并有效处理复杂 UI 元素。
- **基于虚拟机 (VM) 的互动**:如 Anthropic 的 Computer Use 系统在虚拟机 (VM) 环境中运行。它们以更类似人类的方式与应用互动。与 Playwright 的自动化浏览器不同,这些系统使用标准浏览器安装。这使得它们的行为几乎无法与真实人类用户区分。
# 确定 AI 机器人 (AI bots) 活动的规模
首先,您需要了解 AI 机器人 (AI bots) 如何影响您的应用及其规模。将 AWS WAF Bot Control 规则组添加到您的资源保护包中,使用 Common Inspection 级别。最初使用 Count 模式监控流量模式。这种方法允许您分析机器人 (bots) 活动,然后再进行可能影响生产流量的更改。
Bot Control Common 规则组通过签名验证检查自我识别的机器人 (bots)。它包括一个 `CategoryAI` 规则,用于检测已验证的 AI 机器人 (AI bots)。确保将规则组配置为最新版本,如图 1 所示。
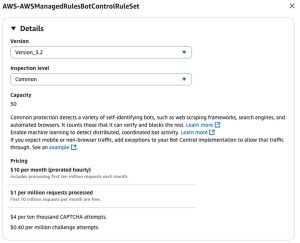
图 1: AWS WAF Bot Control 规则组,使用 Common inspection 级别和版本 3.2
运行托管规则组几天后,您可以分析收集的数据。要查看洞察,请打开 AWS WAF 和 [AWS Shield](https://aws.amazon.com/shield/) 控制台,选择您的 [AWS Region](https://aws.amazon.com/about-aws/global-infrastructure/regions_az/)。选择您的保护包,然后选择 **查看仪表板**。导航到 **概览** 部分,选择 **机器人 (Bots)** 选项,以查看机器人 (bots) 活动、检测、类别和信号。该仪表板提供有关您应用上机器人 (bots) 活动的洞察。
图 2 显示了 **机器人 (Bot)** 类别部分的示例。它显示了大量标记为 `ai - AllowedRequests` 的请求。这些是 AI 机器人 (AI bots),由 `CategoryAI` 规则识别但未被阻塞。您可能还会注意到其他机器人 (bots) 发送大量请求。
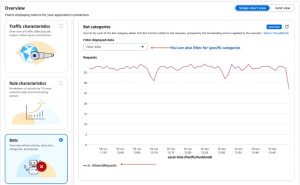
图 2: AWS WAF 检测到的 CategoryAI 规则的流量概览
# 管理 AI 机器人 (AI bots) 引起的问题
在以下部分中,我们讨论管理 AI 机器人 (AI bots) 引起的问题的不同方法。
## 使用 `robots.txt` 及早停止 AI 机器人 (AI bots)
### 场景 1: 及早停止行为良好的 AI 机器人 (AI bots)
[robots.txt](https://en.wikipedia.org/wiki/Robots.txt) 文件有助于控制机器人 (bots) 访问您的应用。此简单文本文件放置在您的应用根目录 (/robots.txt)。它使用标准格式指导合规机器人 (bots) 哪些部分可以和不可以访问。虽然并非所有机器人 (bots) 都遵循这些规则,但信誉良好的机器人 (bots) 操作者会尊重正确配置的 robots.txt 文件。开源项目如 [ai.robots.txt](https://github.com/ai-robots-txt/ai.robots.txt) 提供了一个包含最新 AI 相关爬虫的 `robots.txt`,您可以使用它来阻止这些机器人 (bots) 开始爬取您的应用。
如果 AWS WAF 显示特定机器人 (bots) 的高请求量,则可以使用 `robots.txt` 停止过度活跃且行为良好的抓取机器人 (bots)。这有助于防止它们影响您的 DTO 和应用性能。
以下是示例,允许 Amazon [Amazonbot](https://developer.amazon.com/amazonbot) 爬取 `/public` URL,但不爬取 `/private` URL。
`User-agent: Amazonbot`
`Disallow: /private/`
`Allow: /public/`
### **场景 2: 管理 AI 机器人 (AI bots) 如何使用您的数据**
来自主要科技公司的机器人 (bots) 具有双重目的:它们一次抓取您的应用,并使用数据进行搜索索引和训练 AI 模型。您可以允许这些机器人 (bots) 为搜索索引爬取您的应用,同时请求它们不要将此数据用于训练 LLMs。以下是三个示例,展示如何防止主要机器人 (bots) 操作者使用您的数据训练 LLMs:
**1.** **Amazonbot**:它使用 HTTP 响应头 `X-Robots-Tag: noarchive` 来表示您不希望此响应用于训练 LLMs。您可以使用 CloudFront [响应头策略](https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/modifying-response-headers.html) 将此头添加到您的应用的每个响应中。
`HTTP/1.1 200 OK`
`Date: Tue, 15 Oct 2024 08:09:00 GMT`
`X-Robots-Tag: noarchive`
**2.** **Applebot**:您可以通过在 `robots.txt` 中添加条目 [User-agent Applebot-Extended](https://support.apple.com/en-us/119829) 请求 Apple 不使用来自您应用的数据训练其机器学习 (ML) 模型。这仍允许 Apple 为搜索索引您的内容。以下是示例条目,禁止 Applebot-Extended 访问您的整个应用:
`User-agent: Applebot-Extended`
`Disallow: /`
`User-agent` 指令在 `robots.txt` 中具有特定目的。它与机器人 (bots) 声明的身份匹配,这与 [HTTP User-Agent](https://developer.mozilla.org/en-US/docs/Web/HTTP/Reference/Headers/User-Agent) 头不同。
**3.** **Googlebot**:类似地,Google 允许您通过在 `robots.txt` 中添加 User Agent Google-Extended 来 [禁止训练](https://blog.google/technology/ai/an-update-on-web-publisher-controls/) 其 ML 模型:
`User-agent: Google-Extended`
`Disallow: /`
某些机器人 (bots) 操作者可能不遵守 `robots.txt` 文件,因此您必须使用 AWS WAF 管理它们。
## 使用 AWS WAF
### 场景 3: 管理导致性能低下和高成本的 AI 机器人 (AI bots)
积极抓取您应用数据的 AI 机器人 (AI bots) 可能会降低应用性能并产生高 DTO 和计算费用。您可以使用以下 AWS WAF 技术保护您的应用免受不遵守 `robots.txt` 的机器人 (bots) 的影响:
#### 1. 使用 AWS WAF Bot Control 规则组的 Common Inspection 级别管理自我识别的 AI 机器人 (AI bots):
我们可以删除之前设置为 Count 的 **Override all rules action**,以在 AWS WAF Bot Control 规则组的 Common Inspection 级别中阻塞高容量 AI 机器人 (AI bots) 请求。`CategoryAI` 规则现在默认阻塞这些 AI 机器人 (AI bots) 请求。
除了 `CategoryAI` 规则下的 AI 机器人 (AI bots) 外,AWS WAF 不会阻塞常见且可验证的机器人 (bots)。如果您识别出某个已验证的机器人 (bots) 或机器人 (bots) 类别仍在驱动高流量,则必须在 AWS WAF Bot Control 规则组之后显式添加规则。此规则应阻塞特定机器人 (bots)(或由 [标签命名空间](https://docs.aws.amazon.com/waf/latest/developerguide/waf-rule-label-requirements.html) 表示的机器人 (bots) 类),如图 3 所示。
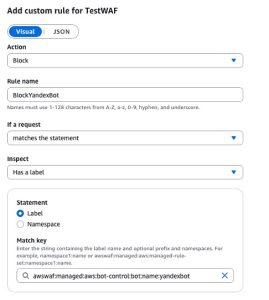
图 3: 使用标签阻塞 yandexbot 的 AWS WAF 自定义规则
#### 2. 减缓逃避性抓取器:
机器人 (bots) 会伪造 HTTP 用户代理头,以假装成知名机器人 (bots) 或合法用户客户端。您可以使用 [AWS WAF 增强型应用层 (L7) DDoS](https://aws.amazon.com/about-aws/whats-new/2025/06/aws-waf-automatic-application-layer-ddos-protection/) 保护以及 [AWS WAF 基于速率的规则](https://docs.aws.amazon.com/waf/latest/developerguide/waf-rule-statement-type-rate-based.html) 来停止这些机器人 (bots) 淹没您的应用。DDoS 规则和速率限制规则可保护您的应用免受任何来源的高请求量,包括机器人 (bots)。要了解如何识别基于速率的规则阈值和创建最佳实践,请参考帖子 [三个最重要的 AWS WAF 基于速率的规则](https://aws.amazon.com/blogs/security/three-most-important-aws-waf-rate-based-rules/)。
#### 3. 让逃避性抓取器为此付出代价:
[AWS WAF Challenge](https://aws.amazon.com/blogs/networking-and-content-delivery/protect-against-bots-with-aws-waf-challenge-and-captcha-actions/) 操作在客户端环境中运行无声挑战,而不需用户互动,且不打算对用户体验产生明显影响。该挑战要求客户端完成计算密集型任务(工作证明)。这种方法旨在为合法用户提供无缝验证机制,同时增加机器人 (bots) 操作者试图与您的应用互动的成本。
图 4 显示了如何在 AWS WAF Bot Control 规则组之后添加自定义规则。此规则要求用户完成挑战后才能继续,除非他们是允许/已验证的机器人 (bots)。已验证的机器人 (bots) 通过命名空间 `awswaf:managed:aws:bot-control:bot` 中的标签来识别。
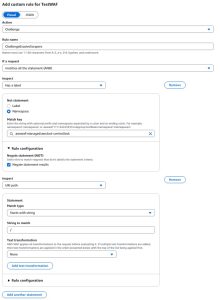
图 4: AWS WAF 规则,用于强制非已验证机器人 (bots) 流量完成挑战
#### 4. 使用蜜罐捕获逃避性机器人 (bots):
[Security Automations for AWS WAF](https://aws.amazon.com/solutions/implementations/security-automations-for-aws-waf/) 包括一个 [蜜罐端点](https://docs.aws.amazon.com/solutions/latest/security-automations-for-aws-waf/embed-the-honeypot-link-in-your-web-application-optional.html),它引诱爬取您应用的机器人 (bots) 访问一个端点,而该端点不会被合法用户或行为良好的机器人 (bots) 访问。该端点会阻塞这些 IP,从而限制机器人 (bots) 抓取您应用的影響。
### 场景 4: 管理不需要的自动化/代理 AI 机器人 (AI bots)
您可以使用以下技术管理代理 AI 机器人 (AI bots):
1. **AWS WAF Bot Control 规则组的 Common Inspection 级别**:`CategoryAI` 规则包括针对已识别 AI 代理 (AI agents) 如 Amazon Nova Act 的规则。此外,`SignalNonBrowserUserAgent` 和 `SignalAutomatedBrowser` 规则将阻塞 Playwright 风格的浏览器自动化代理 (agents)。
2. **AWS WAF Bot Control 规则组的 Targeted Inspection 级别**:此检查级别创建流量模式的智能基线。它使用指纹技术帮助保护您的应用免受模仿人类的代理机器人 (bots)。请参考帖子 [检测并阻塞高级机器人 (bots) 流量](https://aws.amazon.com/blogs/security/detect-and-block-advanced-bot-traffic/) 以获取设置指南。
3. **AWS WAF CAPTCHA 操作**:主要提供者的 LLMs 被训练为不解决 CAPTCHA。这将阻止许多代理 (agents) 完成请求的互动。与之前的 Challenge 技术类似,您可以配置一个带有 CAPTCHA 操作的规则,以需要某些请求完成。请参考帖子 “[使用 AWS WAF CAPTCHA 保护您的应用免受常见机器人 (bots) 流量](https://aws.amazon.com/blogs/security/use-aws-waf-captcha-to-protect-your-application-against-common-bot-traffic/)” 以获取设置指南。
4. **身份验证 (包括生物识别)**:最终,机器人 (bots) 将继续改进并规避缓解措施。如果您对人类互动有严格要求,则考虑在使用身份验证(包括生物识别)之前继续互动。请参考帖子 “[如何使用 AWS WAF Bot Control 针对机器人 (bots) 信号并通过自适应用户体验缓解逃避性机器人 (bots)](https://aws.amazon.com/blogs/networking-and-content-delivery/how-to-use-aws-waf-bot-control-for-targeted-bots-signals-and-mitigate-evasive-bots-with-adaptive-user-experience/)” 以获取驱动自适应用户身份验证的指南,当互动指示可能为机器人 (bots) 流量时。
# 结论:
AI 机器人 (AI bots) 通过过量抓取导致性能下降和成本增加、未经授权使用内容进行 AI 训练,以及从烦人到恶意的自动化互动,制造了重大挑战。通过实施本帖子中讨论的策略,从基本的 `robots.txt` 配置到高级 AWS WAF Bot Control 规则、速率限制和 CAPTCHA 挑战,您可以保护免受未经授权的数据抓取、防止性能下降,并维护对 AI 机器人 (AI bots) 使用您内容的控制。
此外,要保持 AWS WAF 的最新状态,请参考 [AWS WAF 安全博客](https://aws.amazon.com/blogs/security/tag/aws-waf/) 和 [AWS 安全、身份和合规性最新动态](https://aws.amazon.com/about-aws/whats-new/security_identity_and_compliance/?whats-new-content.sort-by=item.additionalFields.postDateTime&whats-new-content.sort-order=desc&awsf.whats-new-products=general-products%23aws-waf)。
感谢阅读本帖子。如果您对本帖子有反馈,请在评论部分提交。如果您对本帖子有问题,请在 [AWS WAF re:Post](https://repost.aws/tags/TAKdJ093DSSdGOQ1VVKX4EvQ/aws-waf) 上启动新线程,或联系 [AWS Support](https://console.aws.amazon.com/support/home)。
# 作者:
(原文作者信息未提供完整,以实际内容为准)
<!-- AI_TASK_END: AI全文翻译 -->